
While working together with the IOStack folks on a paper that shows how storlets can be used to boost spark SQL workloads, two colleagues brought the idea of doing machine learning with Storlets. Out of sheer ignorance I was against the idea thinking that machine learning is not a good fit for storlets as it requires a lot of random access to the data. I was wrong. Now that I am a little less ignorant about machine learning, I can say that storlets can be useful for machine learning in several ways which I describe in this blog.
Data Preparation
It is a well known fact that withing the machine learning “workflow” data cleaning and formatting takes much (if not most) of the time. Object stores are full of unstructured data that must go through some formatting in order to be ‘presented’ to either a training algorithm or to a trained model.
Another example is creating synthetic data based on real data. In a recent demo that features face recognition deep learning with Storlets (the code is here), I showed how storlets are used to extract faces from pictures and format them so that they can be fed into a learning algorithm. Specifically, I wrote an extract_face storlet using OpenCV.
The extract_face storlet finds a bounding box for the face, crops that bounding box and resizes it to a fixed size. The same fixed size is used across all pictures in the training set. Resizing is of particular importance as the learning algorithm ‘anticipates’ that different data points in the training set are of the same ‘format’. Clearly, different pictures feature different sizes of faces. Those operations are fundamental in OpenCV, and there is nothing new about them. The picture below demonstrates how the strorlet works and used with the storlets copy semantics. In the storlets copy semantics the copy target object is the storlet’s output over the copy source object. Using the copy semantics one can prepare a very large training set without any external bandwidth consumption.
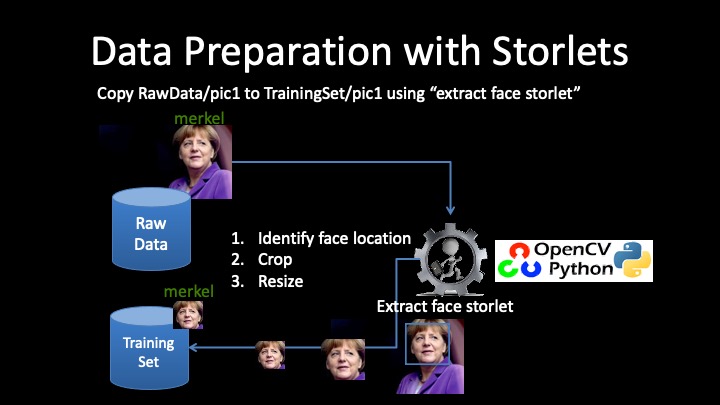
Model Application
Another way to use storlets in the context of machine learning is to apply an already trained model over existing data in the object store. In the above mentioned demo I showed how a face recognition trained model can be used to tag frames in a video with the name of the person appearing in that frame. This was done using a face recognition storlet that leverages OpenCV and scikit-learn. Here we also use the storlets copy semantics which can also be fed with auxiliary objects, in this case the trained model. This is illustrated in the picture below.
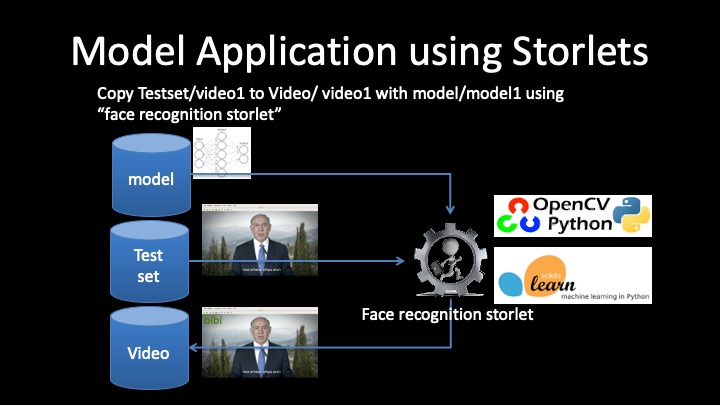
The face recogniton storlet takes two input objects: (1) A trained model, and (2) a video featuring a person that appeared in the training set. The storlet uses the same procedure described above to extract the face. This is done on each frame of the video, and the extracted face is presented to the trained model. The model returns its classification result. Again, using the copy semantics the storlet can create a tagged version of the video with a name appearing on each frame without any external communication. Another way to use the model would be to use a storlet that would enrich the video with a user defined metadata carrying the name that appeared the maximum number of times across all frames.
Model Training
Finally, the demo also shows how storlets can be used to train a neural network using a training set:

The storlet takes all the extracted face objects as inputs and outputs a trained model. Here we use again the storlets copy semantics that accepts multiple objects as input. Each of the extracted faces carries a metadata key with a name from which the storlet builds a supervised learning training set and presents it to a neural network-learning algorithm.
Training with Storlets – Really?
While it is arguable that deep learning, being more compute than data intensive, is a good fit for storlets, other types of learning do seem a good fit. One such type of learning is Stochastic Gradient Descent (SGD) or more precisely mini batched SGD. In mini batched SGD the data is presented to the algorithm in small batches. That is, the algorithm learns iteratively, where in each iteration, a new portion of the training data is being used. This type of algorithm facilitates learning huge amounts of data that cannot fit into memory. When using SGD, special care should be taken to randomly shuffle the data before it is fed into the algorithm as order may make a difference. Also, sometimes one needs to use the same data to the algorithm more than once.
The mlstorlets repository
mlstorlets is an initial implementation of SGD regression and classification classes using storlets. The mlstorlets repository is based on Python’s scikit-learn library and provides Python classes for regression and classification that can be trained using both local and remote data that reside in Swift. Each class supports the methods:
- fit
- remote_fit
The fit method is the scikit-learn usual method for training the model on a given training set. remote_fit, however, takes a Swift object path as a parameter. The idea is that once invoked on a remote data object, the state of the model is serialized, and sent as a parameter to a storlet that creates an instance of the model and feeds it with the data specified in the given path. Once the remote learning is done the updated model is serialized back transparently, updating the local instance on which remote_fit was called.
To summarize, doing machine learning takes much more than running a learning algorithm. In fact most of the work in real systems that do machine learning has to do with data preparation. This is where storlets can probably be of most use. However, storlets can also be of use where the training data set does not fit into memory and batched SGD is a way to go.
Leave a Reply